
目标检测域内,传统一点的框架会在feature map(或者原图)上进行region proposal提取出可能有物体的部分然后进行分类,这一步可能非常费时,所以SSD就放弃了region proposal,而选择直接生成一系列defaul box(或者叫prior box),然后将这些default box回归到正确的位置上去,整个过程通过网络的一次前向传播就可以完成,非常方便。
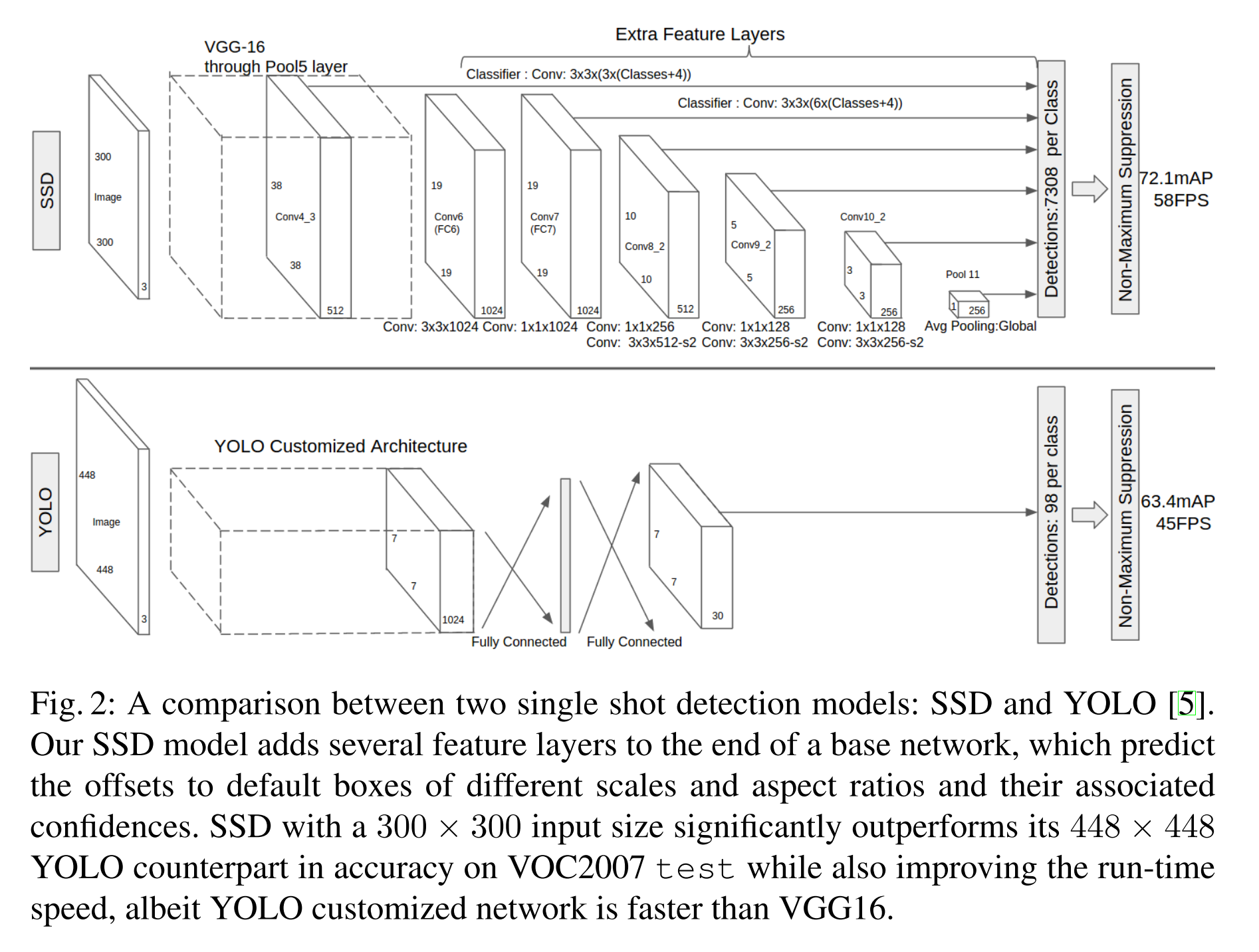
SSD 是基于一个前向传播 CNN 网络,产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性,即 score。之后,进行一个 非极大值抑制(Non-maximum suppression) 得到最终的 predictions。SSD算是YOLO的多尺度版本,由于YOLO对小目标检测效果不好,所以SSD在不同的feature map上分割成grid然后采用类似RPN的方式做回归。
SSD在基础网络结构后,添加了额外的卷积层(没有用全链接层),使得这些卷积层的大小是逐层递减的,所以可以在多尺度下进行 predictions。
- feature map cell 就是将 feature map 切分成 8×8 或者 4×4 之后的一个个的格子;
- default box 就是每一个格子上,一系列固定大小的 box,即图中虚线所形成的一系列 boxes。
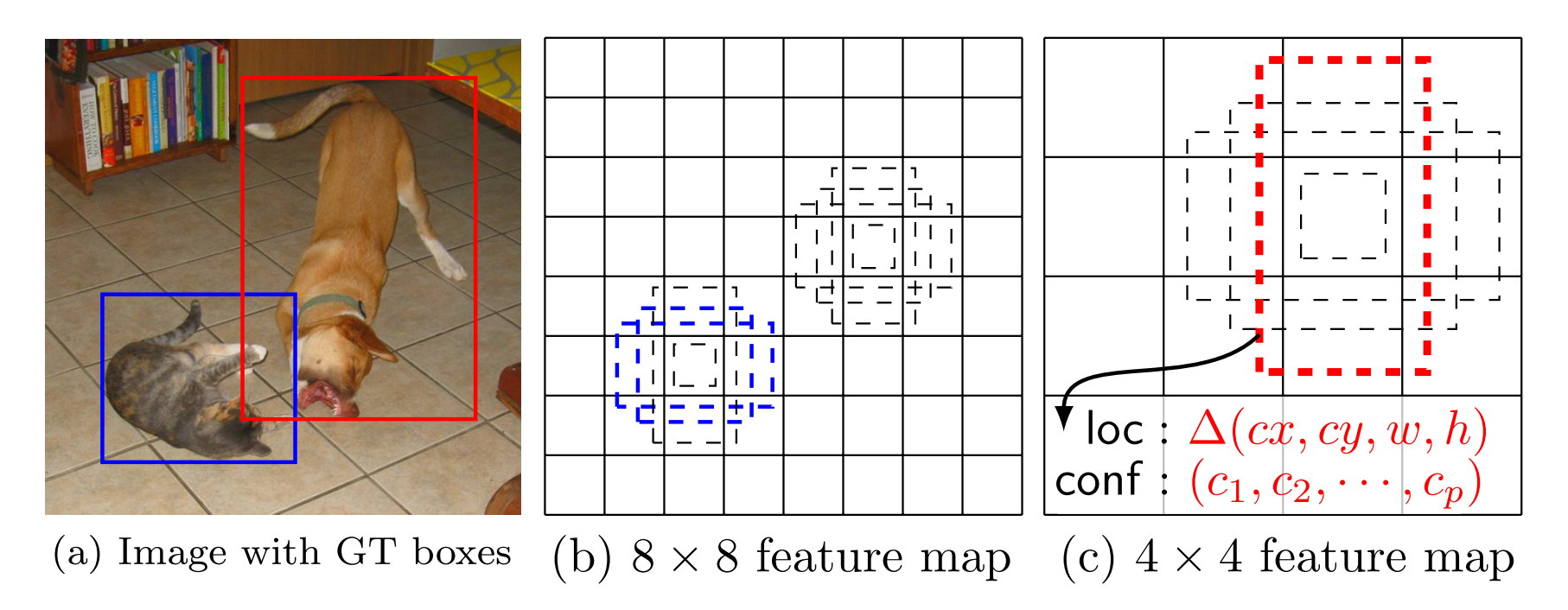
每一个 box 相对于与其对应的 feature map cell 的位置是固定的。 在每一个 feature map cell 中,我们要 predict 得到的 box 与 default box 之间的 offsets,以及每一个 box 中包含物体的 score(每一个类别概率都要计算出)。 因此,对于一个位置上的 kk 个boxes 中的每一个 box,我们需要计算出 cc 个类,每一个类的 score,还有这个 box 相对于 它的默认 box 的 4 个偏移值(offsets)。于是,在 feature map 中的每一个 feature map cell 上,就需要有 (c+4)×k(c+4)×k 个 filters。对于一张 m×nm×n 大小的 feature map,即会产生 (c+4)×k×m×n(c+4)×k×m×n 个输出结果。
在生成一系列的 predictions 之后,会产生很多个符合 ground truth box 的 predictions boxes,但同时,不符合 ground truth boxes 也很多,而且这个 negative boxes,远多于 positive boxes。这会造成 negative boxes、positive boxes 之间的不均衡。训练时难以收敛。
因此,本文采取,先将每一个物体位置上对应 predictions(default boxes)是 negative 的 boxes 进行排序,按照 default boxes 的 confidence 的大小。 选择最高的几个,保证最后 negatives、positives 的比例在 3:1,这样的比例可以更快的优化,训练也更稳定。
源码里使用pycaffe定义网络:http://blog.csdn.net/u011762313/article/details/48213421
本文摘自互联网,是方便自己再次查阅回顾。若有侵权问题可联系邮箱lc438732659@163.com。

